Tagged{Text}
By: Kenneth Stauffer
NONAME@MYSITE.com
August 6th, 2022
Introduction
Here is a description of Tagged{Text}, a very simple file format for organizing text documents.
NOTE: This website was constructed using Tagged{Text}. To the see the source file used to generate this page, click here.
Example
The following is a snippet of text which would qualify as a Tagged{text} document:
P{
This is a I{simple} example of B{Tagged{Text}}. Here is a program:
Code<<_EOF_
main()
{
printf("Hello, World!\n");
}
_EOF_
}
P{Click LINK{here URL{http://wwww.url.com?abc90} to visit site.}
P{Escape chars: '\{' and '\}' and '\\'}
This example demonstrates every feature of Tagged{Text}. A Tagged{Text} document is broken down into the following constructs:
-
Tags:
These are introduced via the use of curly braces, preceeded by a tag name. -
Heredocs:
There is one Heredoc in this example, with its own tag name Code. Heredocs allow blocks of text to be introduced which will not be interpreted. -
Words:
Words are any whitespace seperated text that is not a Tag or a Heredoc. -
Escape Character:
The escape character is the backslash \. It may only preceed the characters {, }, < and \. -
White-space:
White-space is used to delimit words and the beginning of tags and heredocs. Whitespace conists of space, tab and newline characters. Except for delimiting constructs whitespace is stripped from the Tagged{Text} tree. Only in heredocs is whitespace preserved.
Tagged{ Text} is a file format for tagging and organizing text with tags. These tags can be whatever the author wishes them to be. For example the I{...} tag used in the example above could mean "italics".
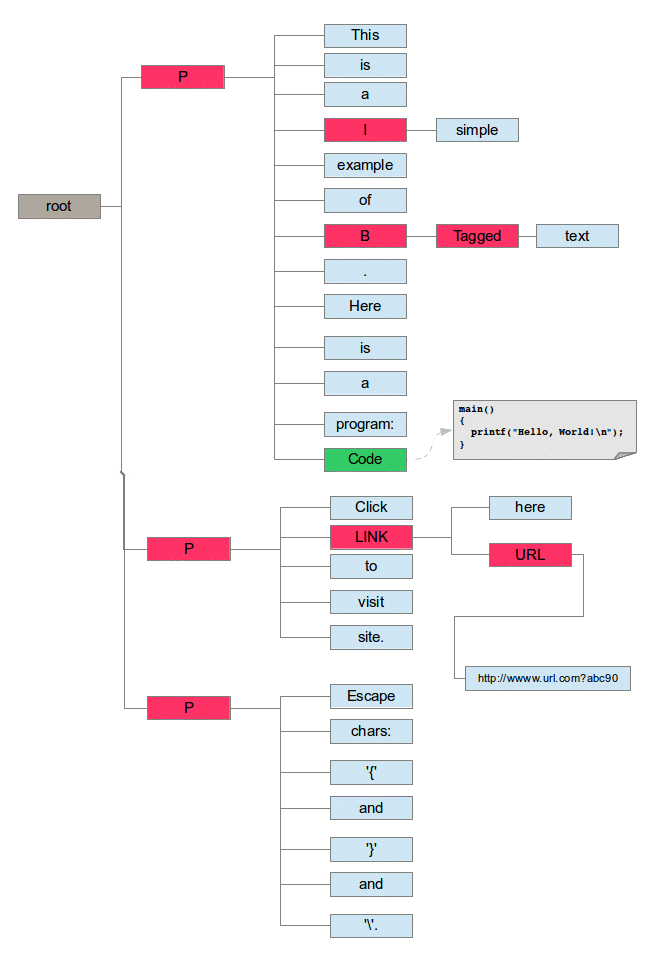
This diagram shows a tree representing the example document. Tagged{Text} documents are always given a root node. Each node can have zero or more children. The order of the children is the order in which they appear in the file. Tags introduce new nodes which can have children. Words and Heredocs do not have children.
A heredoc (Code in this example) consists of the entire block of text that was given. The programming API makes this text available as a list of text lines. Common whitespace (spaces and tabs) are removed from the heredoc. Trailing whitespace is also trimmed. This allows heredocs to be indented in you document for ease of reading. A heredoc uses a delimiter which is _EOF_ in this example. Any text can be used, which will not be part of the text you want to include in the heredoc. All lines of text between Code<<_EOF_ and _EOF_ will be part of the heredoc.
Why use Tagged{Text}?
It is an agnostic markup format, it can be used to form a basis for documents in a static website generator. The author would custom craft python scripts to translate their markup tags into their website. Agnostic means the Tagged{Text} does not enforce any rules or define any meaning to markup tags.
I always like the syntax of TeX and LaTeX from my college days. So I designed Tagged{Text} to have a syntax that reminds me of TeX. Tagged{Text} in my opinion is the simplest file format one can have to structure a text document and not be over burdnoned with gross syntactic elements.
The real power of Tagged{Text} is having programs that can process it. Tree's are very easy structures for computer programs to handle. The recursive solutions that emerge are very clean and simple to reason about.
Blog Entry Example
Here is an example of a Blog entry:
Blog{
Title{What grinds my gears}
Date{2016-3-4}
P{
Ipsum delio gro! Thrunk fo violio of my Streout Santo Listria?
asddsjk kasjdf ksjf ks fks fkfksj dks fksj f
sdfjs f ksf ksfd s
}
P{
Thats all for now. Be back in a few months after I return
from the intl. space station. Oh, here is a cool equation
I wrote in C++:
}
Equation<<_EOC_
E = M C ^ 2
_EOC_
}
This could form the basis of content for a blog section in a website. At this stage you don't care about HTML formatting. Instead focusing on content first. A tool, you must write, would format these entries into HTML or whatever format you want.
The appearance can be tweaked later and never have to concenred with the content when playing around with the appearance. The Blog{} entries never have to be touched, or retouched as you change your mind about formatting.
Summary
That is essentially all you need to know about Tagged{Text}. You annotated text with tags, which are simple identifiers that are case sensitive. I.e., ATag{} I{<...stuff...>} TT{}. You simply invent tags for whatever you feel like doing at the time. My main problem with markdown languages is they are focused on formatting and not semantical meaning. Notice the example above is focused on tagging text based on what is required by a Blog entry. The formatting is a secondary concern.
The first goal of tagged text is to get your document structured according to whatever organizing tags you care about. Whenever you face a new problem of expressing your ideas, just invent tags that structure your text into something sane. Need a slight variation on the bullet list but with each item kinda sorta like a dictionary entry? Then invent that structure. Worry about formatting later. I.e.,
DictList{
Entry{
Word{Frelopiated}
Def{
Snake gloves louisianans luck a now glanced turn expressed recorder
dui discovered ruffian the pyramidal nunc
This is when the floop of their then situa el doriao.
}
}
Entry{
Word{Doorliplidated}
Def{Blah blah. I like turtles. Glaxon}
}
Entry{
Word{Libertanist}
Def{This like floop but with situa el doriao.}
}
Entry{
Word{Junk-lick}
Def{gross list, URL{http:://www.junk-lick.com} see more there.}
}
}
Some interesting constructions:
DEFINE{ MainCharacter{Bob H. Smith} }
DEFINE{ BirthYear{1971} }
P{
My main character in this novel is named MainCharacter{}. He was born
in the year BirthYear{}.
}
A simple macro definition scheme, as shown above.
//{ this is a comment }
A scheme for comments. I wrote a python filter that is run through most of my documents and it removed these comment tags.
include{filename.tt}
HEREDOC{ Code{pythonexample.py} }
I invented an include file mechanism, which opens other files and embeds the Tagged{Text} tree from one document inside the tree of the main document. Also a way to read in a heredoc from an external file.
The tree like structure is easy to craft and mentally visualize. Plus tools exist to dump the tree in various formats, even a GUI using tcl exists. The tree is where is all begins.
Now You can write tools to convert peices of the tree into the final output. How does this work? With a special RawText tree node. This node is understood to be already converted into the final format. Once the entire document consist of nothing but RawRext nodes, then it can be simply emitted as the final output. Just perform an in order traversal of the document tree and emit the pieces of raw text to the output.
The Formatting Problem can be tackled in a variety of ways. One cool way, it so successively rewrite the original tree until it only has tags that are available to a generic HTML formatter.
Then the final pipeline would include this formatter and now you have HTML.
Tagged{Text} is basically a programming language for text. By using a very simple syntax (2 constructs) text files can be organized into a rich tree structure. That is it really. This file format is totally agnostic about formatting. Downstream tools will be responsible for that.
I call these scripts filters. They do not need to perform 100% conversion from the Tagged{Text} tree format to the final output. Instead, they can carve out a piece of the formatting problem and leave the rest alone.
This means an ecosystem of filters can emerge and be combined to achieved different results.
Tagged{Text} lets you invent tags on a whim and worry about the formatting later. For example, say you are documenting your brand new language. So you have tags like this:
Code<<_END_
function foo(a,b,c)
{
d = 100 * a + sine(b)^ * 2 * c;
return d;
}
_END_
But then you wish you could automatically run this code and generate the results. You can! Just invent a tag structure like this:
RunCode{
CodeTag{Example1Code}
ResultTag{Example1Result}
Title{Example 1: Sine function}
LineNumbers{yes}
Code<<_END_
function foo(a,b,c)
{
d = 100 * a + sine(b)^ * 2 * c;
return d;
}
_END_
}
This RunCode{} tag has many features. Basically it will compile the code, run it and store the code in one tag variable, and store the results in another tag variable. Title{} and LineNumbers{} allow you to enrich this tag.
Now you write a python script to pick out these tags and rewrite the Tagged{Text} tree to replace the Example1Code1{} tag with the code. and the Example1Result{} with the result.
As a user of Tagged{Text} you will organically grow your own set of useful filters that can be combined together to generate cool documents.
The filter concept is great, as you can debug each piece of the pipeline by viewing it using 'more' or a graphical viewer (provided. see tt-vis-tree)
Cheat Sheet
Here I document all the tags I have use for this website. The python code for these tags is given also.
Simple Tags
This is B{bold}, I{Italics}, And so on...
Tagged Text File Format
The five syntax elements of Tagged{Text} are:
- Tag
- Word
- Here Document
- Escaping
- White-space
1. Tag
The tag is an arbitrary identifier which begins a new node in the tree with children. The children of this node are enclosed in curly braces.
Foo{this is foo stuff. Now this is Bar stuff: Bar{1 2 3}}
The key parsing requirement for tags is that a word is immediately followed by a open curly brace {. This is what signals to the parser that we are entering a tag.
2. Word
Any non-whitespace text that lacks a trailing curly brace { shall be considered a word. These are all words:
Biteme @@ Hello,There done. (stealth) f(1,2,3)
3. Here Document
You can associate an arbitrary identifier with a bunch of text that is perfectly preserverd and untainted. All whitespace is preserved. All special characters are preserved. This is for things like code and quoting text that you don't want interpreted.
4. Escaping
Escaping is for preventing a couple special characters from being mis-interpreted. The backslash character is the escap character. It is use to escape { and } and < and \. So anytime you wish to use these characters they must be preceeded with the slash.
Futhermore, it is an error for the back slash to preceed any another character.
5. White-space
Except in Here Document, white-space is used only to seperate words. This may seem drastic but I haven't found any cases where it hurts things.
It has the nice benefit that you can indent you document to fit your coding preferences. You can use indenting to give the document the friendly viewing capabilities you want.
Even blank lines have no effect on the Tagged{Text} tree that is created. Inside of Here Document's white space is removed as much as possible too. Whitespace removal is a great normalization of the document.
How to do tables? I prefer using tags that match your specific needs, not writing to a generic way. So rather than invent massive table package and assorted tags, just invent the minimum viable set of tags to accomplish your particular task.
You simply need something pretty to present a nice clean two column table of dates and inflation numbers. Just invent this for now:
KennysSimpleTwoColumnTable{
H{Date} H{Inflation}
D{3/4/68} D{1.2}
D{3/4/78} D{2.2}
D{3/4/88} D{4.2}
D{3/4/98} D{6.2}
}
Another example, one might wish to invent tags like this to keep track of all your dives in text database, then use python to format it nicely for the web.
DiveLog{
Date{2018-03-04}
Time{14:30}
Site{Lake Travis}
Location{Austin, TX}
Duration{45 minutes}
MaxDepth{85 ft}
AirStart{3100 psi}
AirEnd{400 psi}
Temp{65 degrees}
Buddy{Hans Solo}
Equipment{8mm full, hoodie, 90 watt light}
Visibility{20 ft}
Notes{
P{
Dive went well. I saw the plane. I saw a several
giant cat fish around the damn area. My tank slipped out again, had
to take my BCD off and tighten. Saw a group of other divers getting
out when I was getting in.
}
P{
visibility was pretty good, especially at depth.
}
}
}
With Tagged{Text} I can create really elabote macros:
DEFINE{ Bob{
Code<<_EOF_
fhsdjsdf skd
sdfjsdfskdfjk
sdfsdf
sd
f
sdf
sdf
_EOF_
}}
So now the handy tag Bob{} spits out a Here Document into my code.